C++爬虫原理(一):爬虫简介
爬虫简介:
爬虫的主要目的是将互联网上的网页下载到本地,然后通过一系列的数据分析算法等提取有效信息(这也就类似与数据分析)。然而关于c++的爬虫很少(据说python做爬虫有很大的优势,所以 本人也一直努力在学),这几篇就总结一下自己对c++爬虫的理解,沉淀自己的思想。其实所有的爬虫原理大概都是一样的,然才识疏浅,或许有许多自己不知道。
可能理解有误,摸索前进中,希望大牛支出纰漏之处…
爬虫原理图如下:
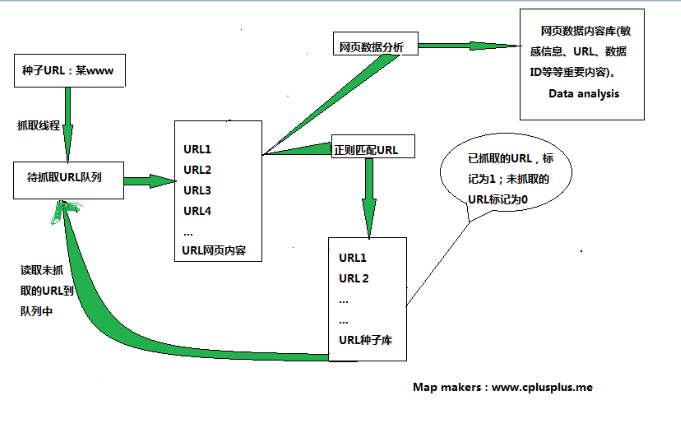
爬虫流程如下:
1、选出种子URL(必须可访问,如果不可访问,爬虫生存周期直接结束)。
2、开启爬虫线程,首先读取种子URL。
3、读取到种子URL内容,一边提取页面的URL,另一方面分析当前页数据。
4、保存提取的URL到“URL库”(已经扫描的置为1,未扫描置为0),另外保存重要的数据到“数据分析库”。
5、线程读取“URL库”中的未扫描链接。
6、…..重复3、4、5操作……
7、爬虫生存周期(可指定:当前域名扫描结束,死亡;或指定:记录扫描深度,超过深度死亡)。
由于时间仓促,下篇将用专业的制图工具介绍详细的内容和流程,然后介绍爬虫的一些读取URL机制等,下篇主要总结:《读取URL策略》。