#Flume# Flume日志采集框架一些知识
一、简介
1.1、介绍
- Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
- Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
- 一般的采集需求,通过对flume的简单配置即可实现
- Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
1.2、运行机制
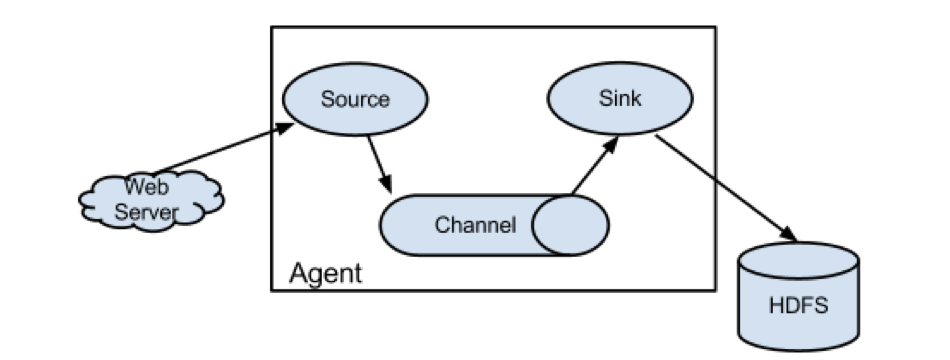
- Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
- 每一个agent相当于一个数据传递员(Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元),内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据(决定了程序运行的位置)
- Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
- Channel:angent内部的数据传输通道,用于从source将数据传递到sink
二、架构图
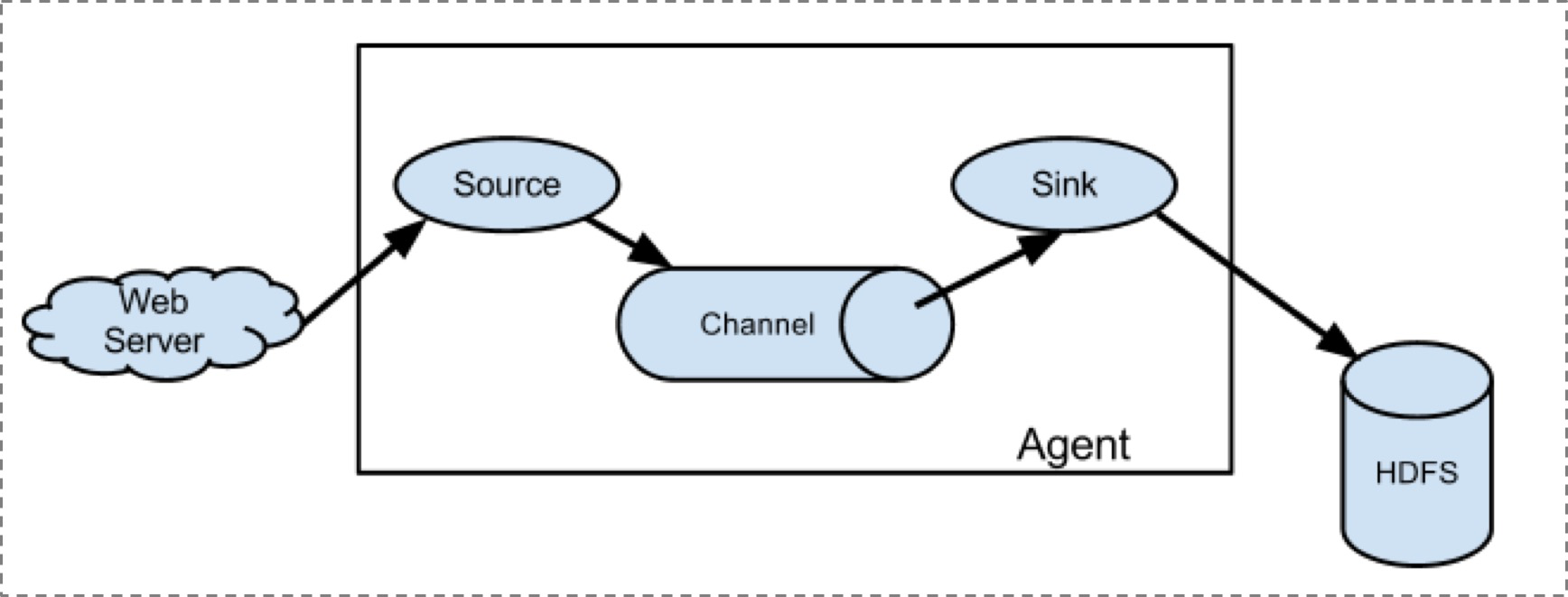
2.1、单agent采集数据
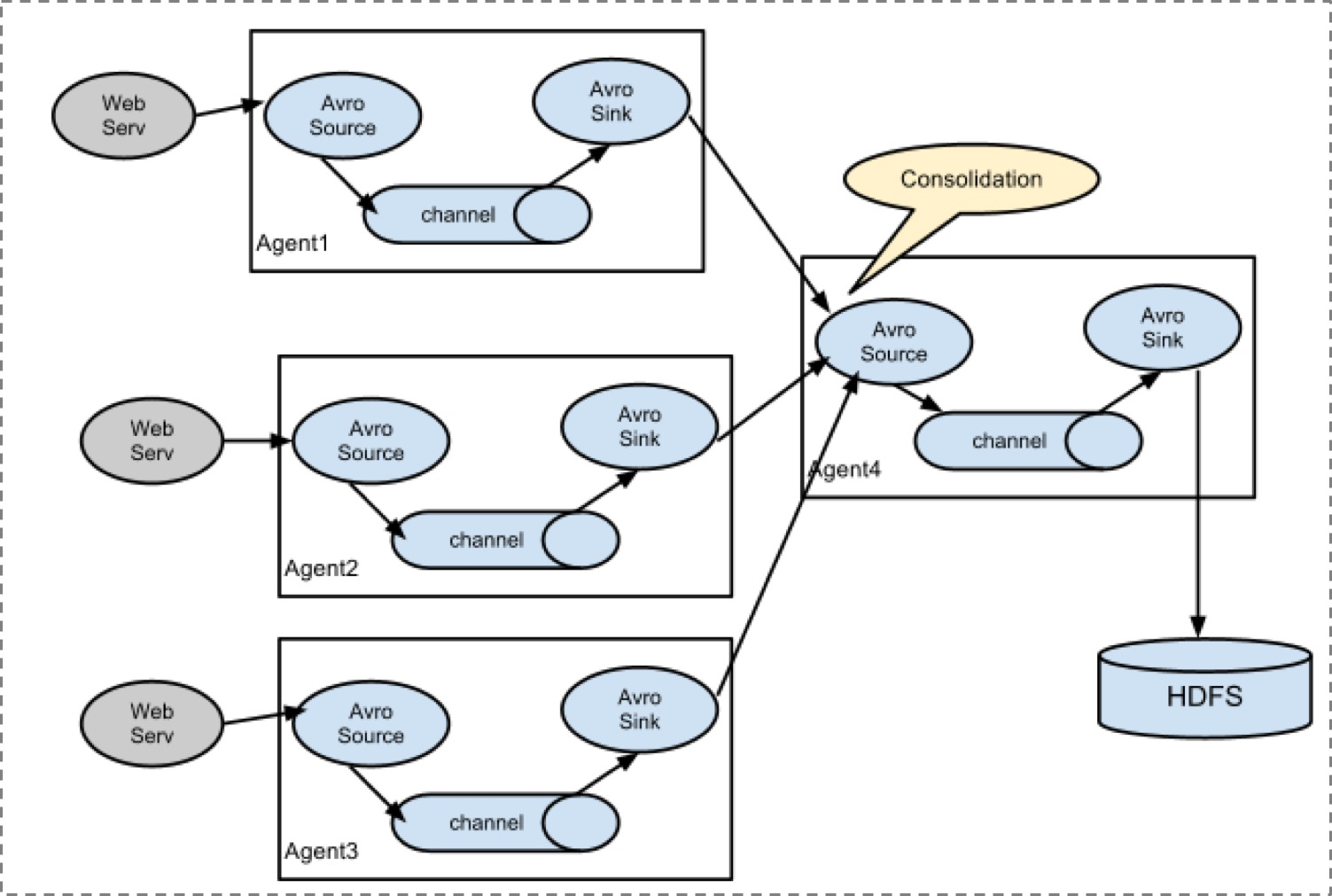
2.2、多级agent串联
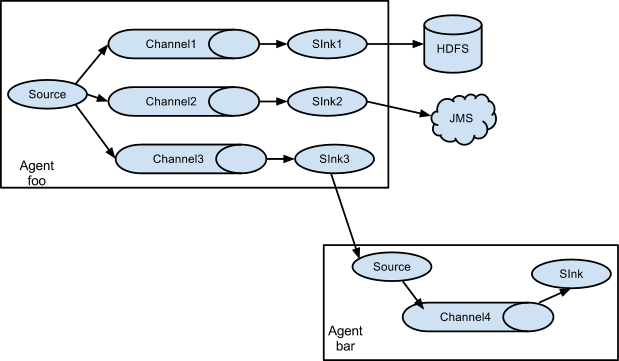
2.3、单数据源多个输出
三、安装
安装配置JDK环境,然后Flume官网下载压缩包,即可使用
四、使用示例
4.1、启动flume,启动命令如下
|
1 |
bin/flume-ng agent -c conf -f conf/flume_conf_file -n a1 -Dflume.root.logger=ERROR,console |
- -c conf 指定flume自身的配置文件所在目录
- -f conf/flume_conf_file 指定我们所描述的采集方案
- -n a1 指定我们这个agent的名字
- -Dflume.root.logger=INFO,console jvm使用,可以换成 DEBUG,INFO,ERROR不同调试日志
4.2、示例一:Socket到log4j
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# Flume采集配置:Socket到log4j # 定义这个agent中各组件的名字,a1是这个agent的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 描述和配置source组件:r1 #netcat监听端口,bind、port是netcat组件的配置 a1.sources.r1.type = netcat a1.sources.r1.bind = master a1.sources.r1.port = 44444 # 描述和配置sink组件:k1 。使用logger组件 a1.sinks.k1.type = logger # 描述和配置channel组件,此处使用是内存缓存的方式,还有一种格式是文件 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 描述和配置source channel sink之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
测试采集数据【产生数据,采集数据】:
产生数据:
|
1 2 3 4 5 6 7 8 |
# telnet master 44444 Trying 192.168.11.101... Connected to master. Escape character is '^]'. hello OK weduoo OK |
采集数据:
|
1 2 3 |
# Flume在INFO模式下输出 (LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. } (LoggerSink.java:94)] Event: { headers:{} body: 77 65 64 75 6F 6F 0D weduoo. } |
4.3、示例二:FlumeToHttpSinks
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
# flume to http agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type=exec a1.sources.r1.command = tail -F /var/log/nginx/access.log # channel-1000000-10000 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 # slinks a1.sinks.k1.type = http a1.sinks.k1.channel = c1 a1.sinks.k1.endpoint = http://xxx.xxx.xxx.xxx/api/get a1.sinks.k1.connectTimeout = 2000 a1.sinks.k1.requestTimeout = 2000 a1.sinks.k1.acceptHeader = application/json a1.sinks.k1.contentTypeHeader = application/json a1.sinks.k1.defaultBackoff = true a1.sinks.k1.defaultRollback = true a1.sinks.k1.defaultIncrementMetrics = false a1.sinks.k1.backoff.4XX = false a1.sinks.k1.rollback.4XX = false a1.sinks.k1.incrementMetrics.4XX = true a1.sinks.k1.backoff.200 = false a1.sinks.k1.rollback.200 = false a1.sinks.k1.incrementMetrics.200 = true # bind a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
4.4、示例三:FlumeToElasticSearch
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # source a1.sources.r1.type=exec a1.sources.r1.command = tail -F /var/log/nginx/access.log # channel-1000000-10000 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 # slinks a1.sinks.k1.type = elasticsearch a1.sinks.k1.hostNames = xxx.xxx.xxx.xxx:9200,xxx.xxx.xxx.xxx:9300 a1.sinks.k1.indexName = xxxName a1.sinks.k1.indexType = xxxType a1.sinks.k1.clusterName = elasticsearch a1.sinks.k1.batchSize = 500 a1.sinks.k1.ttl = 5d a1.sinks.k1.serializer = org.apache.flume.sink.elasticsearch.ElasticSearchDynamicSerializer a1.sinks.k1.channel = c1 # bind a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |